Http Stream
Streams API
Streams API는 javascript를 이용해 네트워크를 통해 전송된 데이터 스트림에 접근하여 원하는 대로 처리가 가능한 API를 제공합니다.
Streaming은 네트워크를 통해 받은 리소스를 작은 조각으로 나누어, bit 단위로 처리합니다.
이는 브라우저가 수신한 자원을 웹페이지에 표현할 때 주로 사용하는 방법입니다.
(Video buffer)는 재생되기 전 천천히 채워지며 가끔 이미지도 천천히 로딩되는 것을 보실 수 있을겁니다.
기존의 javascript에서는 비디오나 텍스트 파일등의 리소스를 처리하기 위해서는,
우선 전체 파일을 다운로드 받은 후, 알맞은 포맷으로 파싱된 후에야, 전송된 데이터를 처리할 수 있었습니다.
Stream API를 이용하면, Buffer, String, Blob 없이도 javascript를 통해 Raw Data를 비트 단위로 처리할 수 있습니다.
Stream API는 stream의 시작과 종료를 감지할 수 있으며, 여러 stream을 엮어서 에러를 처리하거나 필요한 경우 stream을 취소할 수도 있습니다. 또한 stream이 읽어들이는 속도에 따라 반응할 수도 있습니다.
Stream의 주요한 기본 사용법은,
응답 데이터를 stream으로 만드는 것입니다.
fetch request를 통해 정상적으로 전송된 response body는 ReadableStream 으로 표현 가능합니다. 또한 ReadableStream.getReader() 를 통해 Redaer 객체를 얻어 데이터를 읽을 수도 있으며, ReadableStream.cancel() 로 stream을 취소하는 것등이 가능합니다.
WritableStream 을 이용하여 stream에 데이터를 쓰는 것도 가능합니다.
Concept of Streams API
Readable stream 은 javascript의 ReadableStream 객체입니다.
이 객체는 네트워크 혹은 데이터를 얻기 원하는 도메인으로부터 흘러들어오는 underlying source 로부터 생성됩니다.
Underlying source에는 2가지 타입이 있습니다.
-
Push sources: 이 데이터 소스는, 소스에 접근할 때, 지속적으로 데이터를 푸시합니다. 접근을 시작하거나, 중단하거나, 취소하는 것은 당신에게 달렸습니다. 이는 Video streams, TCP/Web sockets 를 예로 들 수 있습니다.
-
Pull sources: 이 데이터 소스는, 당신이 명시적으로 소스에 데이터를 요청하기를 원합니다. 이는 Fetch, XHR을 통한 파일 액세스 를 예로 들 수 있습니다.
이러한 데이터는 chunk 라는 작은 조각들로 순차적으로 읽어들일 수 있습니다.
chunk 는 __1byte가 될 수도 있고, 크기가 큰 _typed array 일 수도 있습니다.
stream 하나는 서로 다른 크기와 타입의 chunk들을 포함할 수 있습니다.
출처: MDN
stream에 chunk가 들어가는 것을 enqueued 된다고 한다.
이것은 chunk가 queue에서 읽어들여지기를 기다린다는 뜻이다.
internal queue 는 아직 읽어들여지지 않은 chunk들을 계속 추적한다.
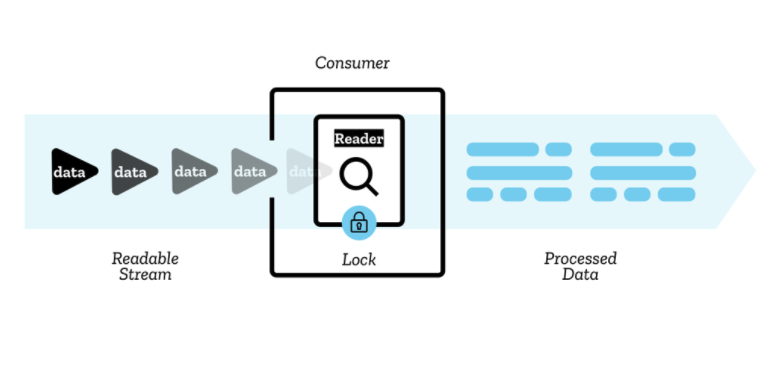
stream 안에 있는 chunk 들은 reader 에 의해 읽어들여진다.
reader 는 한번에 chunk를 하나씩 처리하며, 당신인 원하는 대로 사용할 수 있게한다.
이 reader 와 다른 처리 코드를 하나로 묶은 것을 consumer 라고 한다.
controller 라는 구조체가 있는데, 이는 각각의 reader가 연관된 controller가 있어서 stream을 통제할 수 있게한다.(예를 들면, 원할 때 stream을 닫을 수 있다.)
한번에 하나의 reader만이 하나의 stream을 읽어들일 수 있다.
reader가 생성되고 stream을 읽어들이기 시작하면(active reader), reader가 stream에 locked 되었다고 한다. 만약 다른 reader가 이 stream을 읽어들이기를 원하면, 먼저 기존의 reader를 취소해야한다.
readable stream에는 두가지가 있다.
기존의 readable stream 처럼, byte stream 이라는 타입이 있다. 이것은 byte 소스를 읽어들이기 위한 기존 stream의 확장버전이다. 기존의 readable stream과 다르게, byte streams는 BYOB(bring your own buffer) 로 읽어들일 수 있다. 이러 종류의 reader들은 stream을 버퍼로 그대로 읽어들일 수 있다(copy를 minimizing하는 것이 필요하다). 어느 underlying stream(extension, reader, controller)을 사용할지는 어떻게 처음 stream이 생성되었는지에 달려있다.
Response.body 와 같은 ready-made readable stream을 사용할 수도 있고,
ReadableStream() 생성자를 이용하여 자신만의 stream을 정의할 수도 있다.
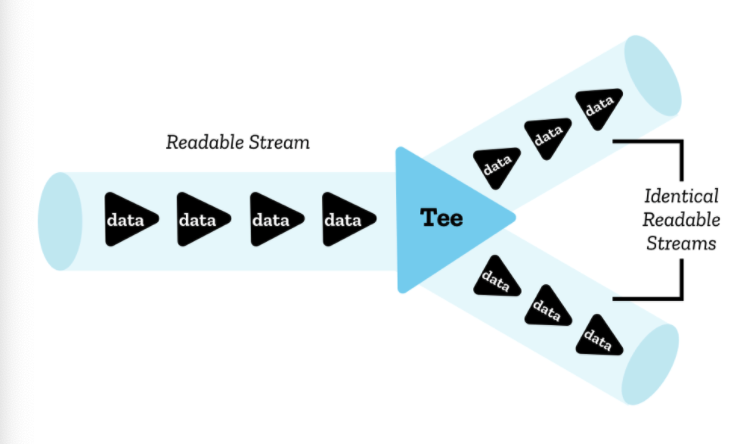
Teeing
한번에 하나의 reader만 stream을 읽을 수 있지만, stream을 두개의 동일한 복사본으로 나눌 수 있다.이렇게 하면 두개의 다른 reader로 읽어들일 수 있다. 이것을 teeing 이라 한다.
ReadableStream.tee() 를 이용할 수 있고, 이는 두개의 동일한 사본을 가지는 배열을 반환한다.
대표적으로 ServiceWorker 를 이용할 때가 있는데, 서버로부터 응답을 받을 때, 브라우저로 파싱하는 stream과 ServiceWorker에 캐싱하는 스트림으로 나누는데 사용할 수 있다.
Writable streams
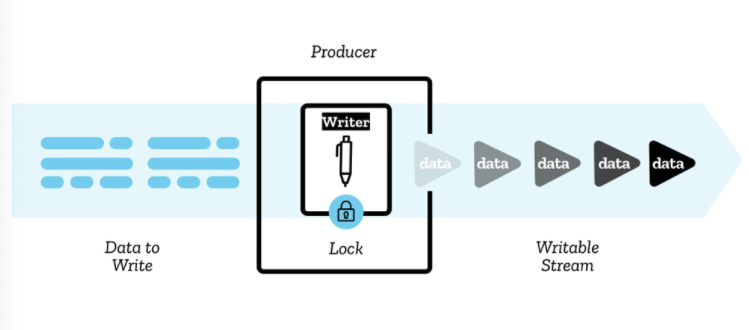
writable stream 은 데이터를 쓸 수 있는 목적지이다.
WritableStream 객체를 생성하여 사용하며, underlying sink 상위의 추상화로서 역할을 한다(raw data가 쓰여지는 lower level I/O sink).
writer를 이용해서 stream에 한번에 하나의 chunk씩 넣을 수 있다.
writer와 그와 연관된 코드의 묶음을 producer 라 부른다.
writer도 한번에 하나의 stream에만 쓸 수 있으며 이 때 active writer가 되고 locked 된다. 역시 다른 writer를 사용하고 싶으면 기존의 writer를 분리하고 새로운 writer를 사용해야한다.
internal queue는 stream에 쓰여진 chunk를 추적하지만, underlying sink 로 처리되지 않은 chunk는 추적히지 않는다.
reader와 같은 controller를 가질 수 있다.
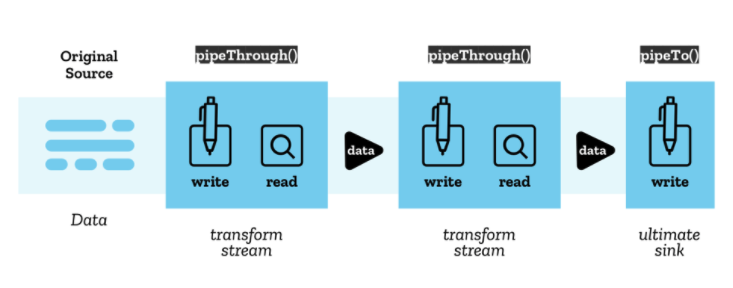
Pipe chains
pipe chain 이라는 구조를 이용해서 stream들을 이어붙일 수 있다.
두가지 메소드가 이를 지원한다.
-
ReadableStream.pipeThrough(): stream을 transform stream 을 통해 이어붙인다. transform stream은 writeable stream과 readable stream의 쌍이며, 이를 통해 기속적으로 데이터를 새로운 상태로 변환한다. 가장 단순한 예는 text decoder로, raw bytes가 써지면, string이 읽어들여진다. 더 다양한 응용은 Transform streams이나 web socket example에서 찾아볼 수 있다.
-
ReadableStream.pipeTo(): pipe chain의 끝 부분으로 작동하는 writable stream으로 이어준다.
pipe chain의 시작은 original source 라 부르고,
마지막은 ulimate sink 라 부른다.
Backpressure
stream의 중요한 개념이다. 이것은 단일 stream이나 pipe chain이 균일게 읽고/쓰는 작업을 가능하게 한다. 만약 나중 stream이 바빠서 더 이상의 chunk를 처리할 수 없을 때, 체인을 통해 뒤로 신호를 보내 앞쪽 transform stream(or original source)가 전달하는 속도를 늦춰 병목현상을 방지한다.
ReadableStream에서 backpressure를 사용하기 위해서는, controller에 consumer에서 요구되는 chunk 크기를 ReadableStreamDefaultController.desiredSize 속성을 이용해 얻고, 만약 이 값이 매우 작으면, 이미 처리하는 용량이 크다는 뜻이므로, ReadableStream이 underlying source에 데이터를 그만 보내게 할 수 있고, backpressure가 stream chain에 가해진다.
만일 다시 데이터를 받을 준비가 되면, pull method 를 이용해 underlying source가 다시 데이터를 보내게 할 수 있다.
Internal queues and queuing strategies
위에 언급된대로, stream 안의 아직 처리되지 않은 chunk들은 internal queue에 의해 추적된다.
- readable stream의 경우, enqueued 되었지만 아직 읽어들여지지 않은 chunk들
- writable stream의 경우, written 되었지만 아직 underlying sink에 의해 처리되지 않은 chunk들
Internal queue들은 queuing strategy를 사용하는데, 이는 어떻게 internal queue state에 기반해 backpressure 신호를 보내는지에 관한 전략이다.
이 전략은 queue 안의 chunk들의 크기를 high water mark(queue가 현실적으로 제어할 수 있는 total chunk의 최대 크기) 라는 값과 비교한다. 계산은 다음과 같이 이루어진다.
high water mark - total size of chunks in queue = desired size
desired size 는 high water mark보다 작으면서 stream flow를 유지할 수 있을 정도의 chunk들의 크기를 말한다. 계산이 끝나면 chunk의 생성 속도의 가/감속이 desired size > 0 인 조건 내에서 가능한 빠르게 stream이 흐를 수 있도록 조정된다.
- desired size <= 0 인 경우는 아직 spec에 정의되지 않았다.(문제를 야기할 수 있다.)
예를 들면, chunk의 크기가 1이고, high water mark가 3이면, 최대 3개까지의 chunk가 enque될 수 있고, 다 차면 backpressure가 적용된다.
